
ParallelClusterでTrainiumを使ってTanuki-8Bをベースにモデル学習してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データ事業本部 インテグレーション部 機械学習チームの中村( @nokomoro3 )です。
以下でParallelClusterの記事を書きました。
本記事ではParallelClusterの活用として、以下のKARAKURI社様の記事を参考にTrainiumを使ったLLMの学習をやってみたいと思います。
本ブログを執筆するにあたり、KARAKURI社様のこの記事が大変参考になりました。ありがとうございます。
前提
まず前提として、上記の記事はComputeNodeとして trn1.32xlarge というインスタンスを使用しますので、料金の発生にはご注意ください。
これに伴いお使いのAWSアカウントの状況によっては、サービスクォータなどの制限を緩和する必要がありますので、ご自身の環境をお確かめください。
ComputeNodeが起動しない、slurm上で起動を繰り返しているように見える場合は、scancelで一旦ジョブを停止して、原因調査にはCloudTrailなどのRunInstanceのログをみると情報が得られると思います。
参考記事はCloudFormationを用いていますが、後学のためにAWSリソースのデプロイはTerraformで、クラスターの作成はpclusterコマンドを用いて行っています。
また参考記事はus-west-2リージョンを使用されていますが、本記事ではus-east-1リージョンを使用します。
実行環境
実行環境は以下となります。
- OS: Windows 10 (WSL2ではない)
- terraform : Terraform v1.6.2 on windows_amd64
- AWS CLI : aws-cli/2.13.15 Python/3.11.4 Windows/10 exe/AMD64 prompt/off
- pcluster : 3.10.1
pclusterなどのセットアップは前回の以下の記事を参考にされてください。
準備
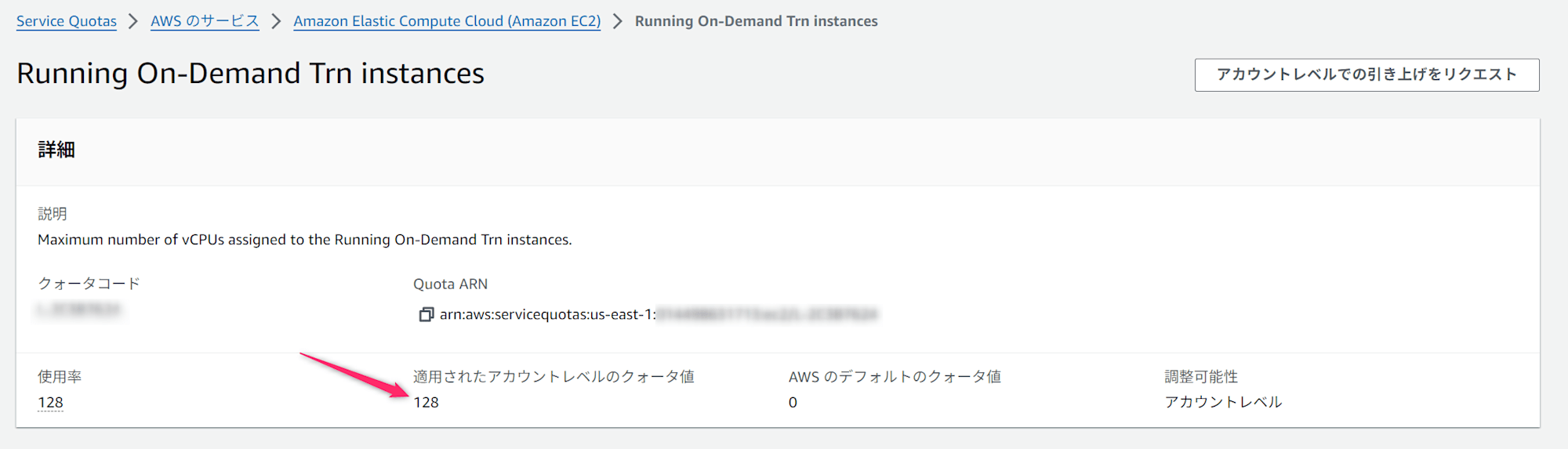
サービスクォータの確認
trn1.32xlarge が必要とするVCPU数は、以下のように1インスタンス分の128以上必要となりますので、ご自身のアカウントでご確認ください。
使用可能なAZの確認
trn1.32xlarge インスタンスですが、すべてのAZで使用できるとは限りません。リージョンごとにこのインスタンスが使えるAZが異なりますので、以下のコマンドで使用可能なAZを調査しましょう。
$ aws ec2 describe-instance-type-offerings \
--location-type availability-zone \
--filters Name=instance-type,Values=trn1.32xlarge \
--region us-east-1
# {
# "InstanceTypeOfferings": [
# {
# "InstanceType": "trn1.32xlarge",
# "LocationType": "availability-zone",
# "Location": "us-east-1b"
# },
# {
# "InstanceType": "trn1.32xlarge",
# "LocationType": "availability-zone",
# "Location": "us-east-1f"
# }
# ]
# }
やってみた
各種リソースの作成
まずはHeadNodeへSSH接続するためのキーペアを作成します。
前回作成したものが残っている場合はそのまま利用いただいてもOKです。
(ただし前回記事はap-northeast-1で行いましたので、今回あらたにus-east-1で私は作成しました)
aws ec2 create-key-pair \
--key-name cm-nakamura-pcluster-key \
--query KeyMaterial \
--output text > cm-nakamura-pcluster-key.pem
VPCは以下のコードでTerraformを使って作成しました。
# リソースプレフィックス
variable "resource_prefix" {
description = "Resource prefix"
type = string
default = "sample-genai"
}
# 変数の定義(リージョン用)
variable "region" {
description = "AWS region"
type = string
default = "us-east-1" # デフォルトリージョンを設定
}
# プロバイダーの設定
provider "aws" {
region = "us-east-1" # 使用するリージョンに変更してください
# 共通タグ
default_tags {
tags = {
Name = "${var.resource_prefix}"
}
}
}
# 利用可能なアベイラビリティーゾーンのデータソース
data "aws_availability_zones" "available" {
state = "available"
filter {
name = "zone-name"
values = ["us-east-1b", "us-east-1f"] # TrainiumとInferentiaが利用可能なAZを指定
}
}
# VPC
resource "aws_vpc" "this" {
cidr_block = "10.0.0.0/16"
enable_dns_hostnames = true
enable_dns_support = true
}
# インターネットゲートウェイ
resource "aws_internet_gateway" "this" {
vpc_id = aws_vpc.this.id
}
# NAT Gateway
resource "aws_nat_gateway" "this" {
allocation_id = aws_eip.natgw.id
subnet_id = aws_subnet.public[0].id
}
# Elastic IPの作成(NAT Gateway用)
resource "aws_eip" "natgw" {
domain = "vpc"
}
# パブリックサブネット(2個)
resource "aws_subnet" "public" {
count = 2
vpc_id = aws_vpc.this.id
cidr_block = "10.0.${count.index + 1}.0/24"
availability_zone = data.aws_availability_zones.available.names[count.index]
map_public_ip_on_launch = true
tags = {
Name = "cm-genai-public-${count.index + 1}"
}
}
# プライベートサブネット
resource "aws_subnet" "private" {
vpc_id = aws_vpc.this.id
cidr_block = "10.0.101.0/24"
availability_zone = data.aws_availability_zones.available.names[0]
tags = {
Name = "cm-genai-private"
}
}
# パブリックルートテーブル
resource "aws_route_table" "public" {
vpc_id = aws_vpc.this.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.this.id
}
}
# パブリックサブネットとルートテーブルの関連付け
resource "aws_route_table_association" "public" {
count = 2
subnet_id = aws_subnet.public[count.index].id
route_table_id = aws_route_table.public.id
}
# プライベートルートテーブルの作成
resource "aws_route_table" "private" {
vpc_id = aws_vpc.this.id
route {
cidr_block = "0.0.0.0/0"
nat_gateway_id = aws_nat_gateway.this.id
}
}
# プライベートサブネットとルートテーブルの関連付け
resource "aws_route_table_association" "private" {
subnet_id = aws_subnet.private.id
route_table_id = aws_route_table.private.id
}
# S3用のVPCエンドポイント(Gateway型)
resource "aws_vpc_endpoint" "s3" {
vpc_id = aws_vpc.this.id
service_name = "com.amazonaws.${var.region}.s3"
}
# S3 VPCエンドポイントとルートテーブルの関連付け
resource "aws_vpc_endpoint_route_table_association" "s3_public" {
route_table_id = aws_route_table.public.id
vpc_endpoint_id = aws_vpc_endpoint.s3.id
}
resource "aws_vpc_endpoint_route_table_association" "s3_private" {
route_table_id = aws_route_table.private.id
vpc_endpoint_id = aws_vpc_endpoint.s3.id
}
# VPCエンドポイント(Interface型)用のセキュリティグループ
resource "aws_security_group" "vpc_endpoint" {
name = "cm-genai-vpc-endpoint"
description = "Security group for VPC endpoints"
vpc_id = aws_vpc.this.id
ingress {
description = "HTTPS from VPC"
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = [aws_vpc.this.cidr_block]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
# CloudWatch Logs用のVPCエンドポイント(Interface型)
resource "aws_vpc_endpoint" "logs" {
vpc_id = aws_vpc.this.id
service_name = "com.amazonaws.${var.region}.logs"
vpc_endpoint_type = "Interface"
private_dns_enabled = true
subnet_ids = [aws_subnet.private.id]
security_group_ids = [aws_security_group.vpc_endpoint.id]
}
# デフォルトセキュリティグループの作成
resource "aws_security_group" "default" {
name = "cm-genai-default"
vpc_id = aws_vpc.this.id
# セキュリティグループ内の全てのインバウンドトラフィックを許可
ingress {
protocol = -1
self = true
from_port = 0
to_port = 0
}
# セキュリティグループ内の全てのアウトバウンドトラフィックを許可
egress {
protocol = -1
self = true
from_port = 0
to_port = 0
}
}
# 出力の修正
output "vpc_id" {
value = aws_vpc.this.id
}
output "public_subnet_ids" {
value = aws_subnet.public[*].id
}
output "private_subnet_id" {
value = aws_subnet.private.id
}
output "default_security_group_id" {
value = aws_security_group.default.id
}
上記ファイルを作成後は以下でデプロイします。
pushd ./infra/vpc
terraform init
terraform apply
popd
また、S3も以下のコードでTerraformを使って作成しました。
# リソースプレフィックス
variable "resource_prefix" {
description = "Resource prefix"
type = string
default = "sample-genai"
}
# 変数の定義(リージョン用)
variable "region" {
description = "AWS region"
type = string
default = "us-east-1" # デフォルトリージョンを設定
}
# プロバイダーの設定
provider "aws" {
region = "us-east-1" # 使用するリージョンに変更してください
# 共通タグ
default_tags {
tags = {
Name = "${var.resource_prefix}"
}
}
}
# S3バケットの作成
resource "aws_s3_bucket" "this" {
bucket = "${var.resource_prefix}"
}
output "bucket_name" {
value = aws_s3_bucket.this.id
}
上記ファイルを作成後は以下でデプロイします。
pushd ./infra/vpc
terraform init
terraform apply
popd
クラスタ設定ファイルの準備
以下のようなクラスタ設定ファイルを準備します。
Region: us-east-1
Image:
Os: ubuntu2004
HeadNode:
InstanceType: c5.4xlarge
Networking:
SubnetId: {作成したパブリックサブネットのID}
Ssh:
KeyName: {作成したキーペア名}
LocalStorage:
RootVolume:
Size: 1024
CustomActions:
OnNodeConfigured:
Script: s3://neuron-s3/pcluster/post-install-scripts/neuron-installation/v2.19.0/u20/pt/install_neuron.sh
Iam:
S3Access:
- BucketName: neuron-s3
EnableWriteAccess: false
Scheduling:
Scheduler: slurm
SlurmSettings:
QueueUpdateStrategy: DRAIN
SlurmQueues:
- Name: compute1
CapacityType: ONDEMAND
ComputeSettings:
LocalStorage:
RootVolume:
Size: 1024
EphemeralVolume:
MountDir: /local_storage
ComputeResources:
- Name: queue1-i1
InstanceType: trn1.32xlarge
MinCount: 0
MaxCount: 8
Efa:
Enabled: true
Networking:
SubnetIds:
- {作成したプライベートサブネットのID}
PlacementGroup:
Enabled: true
CustomActions:
OnNodeConfigured:
Script: s3://neuron-s3/pcluster/post-install-scripts/neuron-installation/v2.19.0/u20/pt/install_neuron.sh
Iam:
S3Access:
- BucketName: neuron-s3
EnableWriteAccess: false
SharedStorage:
- MountDir: /fsx
Name: pclusterfsx
StorageType: FsxLustre
FsxLustreSettings:
DeploymentType: PERSISTENT_2
DataCompressionType: LZ4
StorageCapacity: 1200
PerUnitStorageThroughput: 125
ワークショップ時との差分はいくつかありますが、主な変更点は以下です。
- Neuron SDKをセットアップする
install_neuron.shをHeadNodeとComputeNodeそれぞれのCustomActions.OnNodeConfigured.Scriptに追加 - HeadNodeとComputeNodeそれぞれのインスタンスタイプを、
c5.4xlargeとtrn1.32xlargeに変更 - SharedStorageをEBSからFSx for Lustreに変更
install_neuron.sh ですが、neuron-s3というバケットで公開されていますので、 aws s3 cp で取得することができます。
aws s3 cp s3://neuron-s3/pcluster/post-install-scripts/neuron-installation/v2.19.0/u20/pt/install_neuron.sh
中身は以下のようになっていました。
#!/bin/bash
set -e
echo "Neuron SDK Release 2.19.0"
# Configure Linux for Neuron repository updates
. /etc/os-release
sudo tee /etc/apt/sources.list.d/neuron.list > /dev/null <<EOF
deb https://apt.repos.neuron.amazonaws.com ${VERSION_CODENAME} main
EOF
wget -qO - https://apt.repos.neuron.amazonaws.com/GPG-PUB-KEY-AMAZON-AWS-NEURON.PUB | sudo apt-key add -
# Update OS packages
sudo apt-get update -y
# Install git
sudo apt-get install git -y
# Remove preinstalled packages and Install Neuron Driver and Runtime
sudo apt-get remove aws-neuron-dkms -y
sudo apt-get remove aws-neuronx-dkms -y
sudo apt-get remove aws-neuronx-oci-hook -y
sudo apt-get remove aws-neuronx-runtime-lib -y
sudo apt-get remove aws-neuronx-collectives -y
sudo apt-get install aws-neuronx-dkms=2.17.17.0 -y
sudo apt-get install aws-neuronx-oci-hook=2.4.4.0 -y
sudo apt-get install aws-neuronx-runtime-lib=2.21.41.0* -y
sudo apt-get install aws-neuronx-collectives=2.21.46.0* -y
# Install EFA Driver(only required for multiinstance training)
curl -O https://efa-installer.amazonaws.com/aws-efa-installer-latest.tar.gz
wget https://efa-installer.amazonaws.com/aws-efa-installer.key && gpg --import aws-efa-installer.key
cat aws-efa-installer.key | gpg --fingerprint
wget https://efa-installer.amazonaws.com/aws-efa-installer-latest.tar.gz.sig && gpg --verify ./aws-efa-installer-latest.tar.gz.sig
tar -xvf aws-efa-installer-latest.tar.gz
cd aws-efa-installer && sudo bash efa_installer.sh --yes
sudo rm -rf aws-efa-installer-latest.tar.gz aws-efa-installer
# Remove pre-installed package and Install Neuron Tools
sudo apt-get remove aws-neuron-tools -y
sudo apt-get remove aws-neuronx-tools -y
sudo apt-get install aws-neuronx-tools=2.18.3.0 -y
export PATH=/opt/aws/neuron/bin:$PATH
# Install Python venv and activate Python virtual environment to install
# Neuron pip packages.
sudo apt install python3.8-venv -y
cd /home/ubuntu
. "/etc/parallelcluster/cfnconfig"
if [[ $cfn_node_type == "HeadNode" ]]; then
python3.8 -m venv aws_neuron_venv_pytorch
source aws_neuron_venv_pytorch/bin/activate
pip install -U pip
# Install packages from repos
python -m pip config set global.extra-index-url "https://pip.repos.neuron.amazonaws.com"
python -m pip install torch-neuronx=="2.1.2.2.2.0" neuronx-cc=="2.14.213.0" neuronx_distributed=="0.8.0" torchvision
chown ubuntu:ubuntu -R aws_neuron_venv_pytorch
else
DNS_SERVER=""
grep Ubuntu /etc/issue &>/dev/null && DNS_SERVER=$(resolvectl dns | awk '{print $4}' | sort -r | head -1)
IP="$(host $HOSTNAME $DNS_SERVER | tail -1 | awk '{print $4}')"
DOMAIN=$(jq .cluster.dns_domain /etc/chef/dna.json | tr -d \")
sudo sed -i "/$HOSTNAME/d" /etc/hosts
sudo bash -c "echo '$IP $HOSTNAME.${DOMAIN::-1} $HOSTNAME' >> /etc/hosts"
fi
Neuronのインストールの他、EFAの設定やPythonの仮想環境の作成などが実行されることが分かります。
公式の情報としては以下が参考になるかと思います。
クラスタの作成
クラスタ設定を元に、クラスタを作成します。
pcluster create-cluster --cluster-name {クラスタ名} --cluster-configuration config.yaml
VSCodeのRemote SSH機能でアクセスしたいので、以下をローカルマシンの ~/.ssh/config に記載して接続します。
Host {任意の接続名}
HostName {Head NodeのIPアドレス}
User ubuntu
IdentityFile {pemファイルへのパス}
ワークショップと異なりAmazon LinuxではなくUbuntuを使用していますので、ユーザ名もec2-userからubuntuに変わっている点にご注意ください。
S3とFSx for Lustreの関連付け
S3とFSx for Lustreの関連付けを以下で行います。
fsx_id=$(aws cloudformation describe-stacks \
--stack-name {クラスタ名} \
--query "Stacks[0].Outputs[?OutputKey=='FSXIds'].OutputValue" \
--output text)
これ以降はHeadNodeにSSH接続してからの作業となります。
またこれ以降は参考記事をほぼ踏襲します。
Python実行環境の準備
すでに install_neuron.sh によりPython仮想環境が準備されていますので、以下で有効化します。
source ~/aws_neuron_venv_pytorch/bin/activate
また、トレーニングの実行に使うスクリプトがLlamaを例としてGitHubに配置されていますので、特定のコミット断面でのファイルを以下で取得します。
commit_sha=0f2a90f6ba2dc8fb12833d85e48732ca36717611
wget https://raw.githubusercontent.com/aws-neuron/neuronx-distributed/${commit_sha}/examples/training/llama/tp_zero1_llama_hf_pretrain/logger.py
wget https://raw.githubusercontent.com/aws-neuron/neuronx-distributed/${commit_sha}/examples/training/llama/tp_zero1_llama_hf_pretrain/tp_zero1_llama_hf_pretrain.py
wget https://raw.githubusercontent.com/aws-neuron/neuronx-distributed/${commit_sha}/examples/training/llama/lr.py
wget https://raw.githubusercontent.com/aws-neuron/neuronx-distributed/${commit_sha}/examples/training/llama/modeling_llama_nxd.py
wget https://raw.githubusercontent.com/aws-neuron/neuronx-distributed/${commit_sha}/examples/training/llama/requirements.txt
wget https://raw.githubusercontent.com/aws-neuron/neuronx-distributed/${commit_sha}/examples/training/llama/training_utils.py
wget https://raw.githubusercontent.com/aws-neuron/neuronx-distributed/${commit_sha}/examples/training/checkpoint_converter.py
追加で必要なパッケージをインストールします。
pip install -r requirements.txt
こちらの requirements.txt にはNeuronとは無関係な、transformersやsentencepieceなどのライブラリが記載されていました。
補足:再接続して途中から実行する場合
以降の内容について、仮想環境の有効化と環境変数の設定は、セッションが切れる都度やり直す必要がありますので、再接続時は以下を実行してからやり直しされてください。
source ~/aws_neuron_venv_pytorch/bin/activate
export HF_MODEL_NAME=weblab-GENIAC/Tanuki-8B-dpo-v1.0
export DATA_PATH=/fsx/data/minnade-ichikara
export MODEL_CONFIG_PATH=./tanuki-8b/config.json
export CHECKPOINT_DIR=/fsx/checkpoints
export TP_DEGREE=32
export KV_REPLICATOR=4
export MODEL_OUTPUT_DIR=/fsx/models/tanuki-8b-sft
データセットのダウンロード
以下2つのデータセットを使用します。
- https://huggingface.co/datasets/minnade/chat-daily/tree/2024-07-25
- https://huggingface.co/datasets/p1atdev/ichikara-instruction/tree/main/20231221-003
以下のようなファイルを作成します。
import argparse
import os
from itertools import chain
from datasets import (
Dataset,
Features,
Sequence,
Value,
concatenate_datasets,
load_dataset,
)
from transformers import AutoTokenizer
def minnade_to_oasst(row):
row["message_id"] = row.pop("id")
row["text"] = row.pop("body") or ""
row["replies"] = []
return row
def read_dataset_message_trees(dataset_name: str, split: str, revision: str):
dataset = load_dataset(dataset_name, split=split, revision=revision)
dataset = dataset.sort("created_at")
trees: list[dict] = []
for row in dataset:
row = minnade_to_oasst(row)
if row["parent_id"] is None:
tree_dict = {
"message_tree_id": row["message_id"],
"prompt": row,
}
trees.append(tree_dict)
else:
for tree_dict in trees:
def add_child(node: dict, new_node: dict):
if new_node["parent_id"] == node["message_id"]:
node["replies"].append(new_node)
return
for i, _ in enumerate(node["replies"]):
add_child(node["replies"][i], new_node)
add_child(tree_dict["prompt"], row)
return trees
def create_threads(node, threads, parents=None):
parents = parents or []
if not node:
return
thread = parents + [node]
if not thread[-1]["replies"]:
threads.append(thread)
if node["replies"]:
parents = thread
for c in node["replies"]:
create_threads(c, threads, parents)
def gen_thread(dataset_name: str, split: str, revision: str):
trees = read_dataset_message_trees(dataset_name, split, revision)
threads: list[list] = []
for tree in trees:
create_threads(tree["prompt"], threads)
for thread in threads:
if thread[0]["role"] == "system":
for i, m in enumerate(thread):
if i == 0:
continue
if i % 2 == 0:
assert m["role"] == "assistant", m
else:
m["role"] == "user", m
else:
for i, m in enumerate(thread):
if i % 2 == 0:
assert m["role"] == "user", m
else:
m["role"] == "assistant", m
if thread[-1]["role"] == "user":
thread = thread[:-1]
if thread[-1]["role"] == "system":
thread = thread[:-1]
if thread:
yield {
"messages": [{"role": m["role"], "content": m["text"]} for m in thread]
}
def load_minnade_dataset():
return Dataset.from_generator(
gen_thread,
gen_kwargs={
"dataset_name": "minnade/chat-daily",
"split": "train",
"revision": "2024-07-25",
},
)
def load_ichikara_dataset():
dataset = load_dataset(
"p1atdev/ichikara-instruction", "20231221-003", split="train"
)
return dataset.map(
lambda example: {
"messages": [
{"role": "user", "content": example["text"]},
{"role": "assistant", "content": example["output"]},
]
},
remove_columns=dataset.column_names,
)
def main(args):
save_path = os.path.expanduser(args.data_dir)
if not os.path.exists(save_path):
os.makedirs(save_path)
block_size = args.block_size
features = Features(
{
"input_ids": Sequence(feature=Value(dtype="int32")),
"labels": Sequence(feature=Value(dtype="int32")),
}
)
tokenizer = AutoTokenizer.from_pretrained(args.model_name)
BOS = [tokenizer.bos_token_id]
EOS = [tokenizer.eos_token_id]
BINST = tokenizer.encode("[INST]", add_special_tokens=False)
EINST = tokenizer.encode("[/INST]", add_special_tokens=False)
BSYS = tokenizer.encode("<<SYS>>\n", add_special_tokens=False)
ESYS = tokenizer.encode("\n<</SYS>>\n\n", add_special_tokens=False)
def tokenize(example):
input_ids = []
labels = []
if example["messages"][0]["role"] == "system":
system = example["messages"][0]["content"]
messages = example["messages"][1:]
else:
system = None
messages = example["messages"]
for i, message in enumerate(messages):
if message["role"] == "user":
if i == 0 and system:
tokens = (
BOS
+ BINST
+ BSYS
+ tokenizer.encode(system, add_special_tokens=False)
+ ESYS
+ tokenizer.encode(message["content"], add_special_tokens=False)
+ EINST
)
else:
tokens = (
BOS
+ BINST
+ tokenizer.encode(message["content"], add_special_tokens=False)
+ EINST
)
input_ids += tokens
labels += [-100] * len(tokens)
else:
tokens = (
tokenizer.encode(message["content"], add_special_tokens=False) + EOS
)
input_ids += tokens
labels += tokens
return {"input_ids": input_ids, "labels": labels}
def group_texts(examples):
concatenated_examples = {
k: list(chain.from_iterable(values for values in examples[k]))
for k in features.keys()
}
total_length = len(concatenated_examples[list(features.keys())[0]])
total_length = (total_length // block_size) * block_size
result = {
k: [t[i : i + block_size] for i in range(0, total_length, block_size)]
for k, t in concatenated_examples.items()
}
return result
dataset = concatenate_datasets([load_minnade_dataset(), load_ichikara_dataset()])
dataset = (
dataset.map(
tokenize,
remove_columns=dataset.column_names,
features=features,
)
.shuffle(seed=42)
.map(
group_texts,
batched=True,
)
.shuffle(seed=42)
.filter(lambda example: not all([e < 0 for e in example["labels"]]))
.map(lambda example: {**example, "attention_mask": True})
)
print(dataset)
dataset.save_to_disk(save_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--model_name",
type=str,
help="Model name.",
)
parser.add_argument(
"--data_dir",
type=str,
help="Pre-tokenized dataset directory.",
)
parser.add_argument(
"--block_size",
type=int,
default=8192,
help="Block size.",
)
args = parser.parse_args()
main(args)
環境変数を設定して、実行します。
export HF_MODEL_NAME=weblab-GENIAC/Tanuki-8B-dpo-v1.0
export DATA_PATH=/fsx/data/minnade-ichikara
python get_dataset.py \
--model_name ${HF_MODEL_NAME} \
--data_dir ${DATA_PATH}
--model_name を指定しているのは、このTanuki-8Bモデルのtokenizerがデータセット作成に必要なためのようです。
実行後、以下のようなファイルができていたらOKです。
ls -l /fsx/data/minnade-ichikara
# total 2638
# -rw-rw-r-- 1 ubuntu ubuntu 6031064 Sep 24 07:47 data-00000-of-00001.arrow
# -rw-rw-r-- 1 ubuntu ubuntu 432 Sep 24 07:47 dataset_info.json
# -rw-rw-r-- 1 ubuntu ubuntu 300 Sep 24 07:47 state.json
ベースモデルのcheckpointのダウンロードと変換
ベースとなるモデルのチェックポイントをダウンロードし、NeuronX Distributedで処理可能な形式に変換します。
モデルは既にtokenizerのところでもでてきていますが、以下を使用します。
以下のようなファイルを作成します。
import torch
import torch_xla.utils.serialization as xser
from transformers import AutoConfig, AutoModelForCausalLM
from checkpoint_converter import CheckpointConverterBase
class CheckpointConverterLlama(CheckpointConverterBase):
def load_partial_xser(self, args, tp_rank, pp_rank):
filename = self.get_input_filename(args, tp_rank, pp_rank, 1)
partial_state = xser.load(filename)
partial_state = {k: v.to(torch.bfloat16) for k, v in partial_state.items()}
return partial_state
def save_full(self, args, full_state):
config = AutoConfig.from_pretrained(args.config)
with torch.device("meta"):
model = AutoModelForCausalLM.from_config(config)
model.load_state_dict(full_state, assign=True)
model.save_pretrained(args.output_dir)
def load_full_state(self, args):
model = AutoModelForCausalLM.from_pretrained(args.input_dir, torch_dtype="auto")
if args.vocab_size > 0:
with torch.no_grad():
model.resize_token_embeddings(args.vocab_size)
return model.state_dict()
if __name__ == "__main__":
checkpoint_converter = CheckpointConverterLlama()
parser = checkpoint_converter.get_arg_parser()
parser.add_argument(
"--vocab_size", type=int, default=-1, help="Vocabulary size of the model"
)
args, _ = parser.parse_known_args()
checkpoint_converter.run(args)
Tanuki-8bモデルの設定ファイルをHuggingFaceのページからダウンロードします。
export MODEL_CONFIG_PATH=./tanuki-8b/config.json
mkdir ./tanuki-8b
curl https://huggingface.co/${HF_MODEL_NAME}/raw/main/config.json \
| jq '. + {"vocab_size": 128256, "sequence_parallel_enabled": false, "selective_checkpoint_enabled": false, "move_model_to_device": false}' \
> ${MODEL_CONFIG_PATH}
環境変数を設定して、実行します。
export CHECKPOINT_DIR=/fsx/checkpoints
export TP_DEGREE=32
export KV_REPLICATOR=4
python convert_checkpoints.py \
--input_dir ${HF_MODEL_NAME} \
--output_dir ${CHECKPOINT_DIR}/pretrained_weight \
--config ${MODEL_CONFIG_PATH} \
--tp_size ${TP_DEGREE} \
--kv_size_multiplier ${KV_REPLICATOR} \
--qkv_linear True \
--convert_from_full_state True \
--vocab_size 128256
参考記事のとおり --vocab_size 128256 とすることによってLlama 3 8Bと等価となるため、推論時のモデルのコンパイルを省略することができるようです。
実行後、以下のようなファイルができていたらOKです。
ls -l /fsx/checkpoints/pretrained_weight/model/
# total 17279500
# -rw-rw-r-- 1 ubuntu ubuntu 552847483 Sep 24 08:00 dp_rank_00_tp_rank_00_pp_rank_00.pt
# ...
# -rw-rw-r-- 1 ubuntu ubuntu 552847483 Sep 24 08:01 dp_rank_00_tp_rank_31_pp_rank_00.pt
モジュールの最新化
学習前にいくつかモジュールのバージョン不一致がありましたので、最新化を行いました。
まずはNeuron SDKについてですが、以下を参考に最新化しました。
最新化前のバージョンは以下の通りです。
pip freeze | grep neuron
# aws-neuronx-runtime-discovery==2.9
# libneuronxla==2.0.4115.0
# neuronx-cc==2.14.213.0+013d129b
# neuronx-distributed==0.8.0
# torch-neuronx==2.1.2.2.2.0
最新化を実施します。
python -m pip install --upgrade neuronx-cc==2.* torch-neuronx torchvision
# ...
# Successfully installed ml-dtypes-0.2.0 neuronx-cc-2.15.128.0+56dc5a86 requests-2.31.0 torch-neuronx-2.1.2.2.3.0 torch-xla-2.1.4
次にprotobuf関連でもエラーが発生しましたので、アップグレードをします。
アップグレード前は以下でした。
pip freeze | grep protobuf
# protobuf==3.19.6
最新化を実施します。
python -m pip install --upgrade protobuf
# ...
# Successfully installed protobuf-5.28.2
コンパイルの実行
モデル学習に使用する以下のようなスクリプトを作成します。
#!/bin/bash
#############################################
# User defined parameters and env vars
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
export NEURON_CC_FLAGS="--model-type transformer --distribution-strategy=llm-training --cache_dir=$SCRIPT_DIR/neuron_compile_cache/"
export NEURON_FUSE_SOFTMAX=1
# Async Runtime
export NEURON_RT_ASYNC_EXEC_MAX_INFLIGHT_REQUESTS=3
# HOST OOM
export MALLOC_ARENA_MAX=64
# TP degree
: {TP_DEGREE:=32}
# KV replication size
: {KV_REPLICATOR:=4}
# 0: bf16; 1: mixed precision
USE_MIX_PRECISION=1
# 0: use pure DP; 1: use ZeRO-1
USE_ZERO_1=1
# global batch size
GBS=8
# micro batch size
MBS=1
# number of steps to run
TOTAL_STEPS=100
# warmup steps
WARMUP_STEPS=10
# Model config path
: {MODEL_CONFIG_PATH:="$SCRIPT_DIR/tanuki-8b"}
# Data path
: {DATA_PATH:="$SCRIPT_DIR/data/minnade-ichikara"}
# sequence length
SEQ_LEN=8192
# Checkpoint directory
: {CHECKPOINT_DIR:="$SCRIPT_DIR/checkpoints"}
#############################################
export NUM_NEURONCORES=32
NODE_ID=0
WORLD_SIZE=1
DISTRIBUTED_ARGS="--nproc_per_node $NUM_NEURONCORES"
if [ ! -z "$SLURM_NTASKS" ]; then
WORLD_SIZE=$SLURM_NTASKS
NODE_ID=$SLURM_NODEID
MASTER_ADDRESS=(`scontrol show hostnames $SLURM_JOB_NODELIST`)
DISTRIBUTED_ARGS="--nproc_per_node $NUM_NEURONCORES --nnodes $WORLD_SIZE --node_rank $NODE_ID --master_addr $MASTER_ADDRESS --master_port 44000"
if [ $NODE_ID -eq 0 ]; then
echo "WORLD_SIZE=$WORLD_SIZE"
echo "NODE_ID=$NODE_ID"
echo "MASTER_ADDRESS=$MASTER_ADDRESS"
echo "DISTRIBUTED_ARGS=$DISTRIBUTED_ARGS"
fi
export FI_EFA_USE_DEVICE_RDMA=1
export FI_PROVIDER=efa
fi
echo "WORLD_SIZE=$WORLD_SIZE"
echo "NODE_ID=$NODE_ID"
echo "MASTER_ADDRESS=$MASTER_ADDRESS"
sudo sysctl -w net.ipv4.ip_local_reserved_ports=44000,48620
export NEURON_RT_NUM_CORES=32
export NUM_NEURONCORES=$NEURON_RT_NUM_CORES
export TPU_NUM_DEVICES=$NEURON_RT_NUM_CORES
export TPU_CHIPS_PER_HOST_BOUNDS=$NEURON_RT_NUM_CORES
#############################################
EXTRA_ARGS=" "
if [ $USE_MIX_PRECISION -gt 0 ]; then
EXTRA_ARGS+=" --use_mix_precision"
fi
if [ $USE_ZERO_1 -gt 0 ]; then
EXTRA_ARGS+=" --use_zero_1"
fi
DP=$(($NEURON_RT_NUM_CORES * $WORLD_SIZE / $TP_DEGREE))
ACC_STEPS=$(($GBS / $MBS / $DP))
if [ $NEURON_EXTRACT_GRAPHS_ONLY -gt 0 ]; then
STEPS_THIS_RUN=2
OUTPUT_LOG=log_compile-$NODE_ID.log
elif [ -v PERF_TEST ] && [ $PERF_TEST -gt 0 ]; then
STEPS_THIS_RUN=100
OUTPUT_LOG=log_exe-$NODE_ID.log
else
STEPS_THIS_RUN=-1
OUTPUT_LOG=log_exe-$NODE_ID.log
fi
echo TP_DEGREE=$TP_DEGREE
echo KV_REPLICATOR=$KV_REPLICATOR
echo USE_MIX_PRECISION=$USE_MIX_PRECISION
echo USE_ZERO_1=$USE_ZERO_1
echo GBS=$GBS
echo MBS=$MBS
echo TOTAL_STEPS=$TOTAL_STEPS
echo WARMUP_STEPS=$WARMUP_STEPS
echo MODEL_CONFIG_PATH=$MODEL_CONFIG_PATH
echo DATA_PATH=$DATA_PATH
echo SEQ_LEN=$SEQ_LEN
echo CHECKPOINT_DIR=$CHECKPOINT_DIR
echo EXTRA_ARGS=$EXTRA_ARGS
echo DP=$DP
echo ACC_STEPS=$ACC_STEPS
echo STEPS_THIS_RUN=$STEPS_THIS_RUN
echo OUTPUT_LOG=$OUTPUT_LOG
torchrun $DISTRIBUTED_ARGS \
tp_zero1_llama_hf_pretrain.py \
--model_path $MODEL_CONFIG_PATH \
--data_dir $DATA_PATH \
--tensor_parallel_size $TP_DEGREE \
--batch_size $MBS \
--steps_this_run $STEPS_THIS_RUN\
--max_steps $TOTAL_STEPS \
--warmup_steps $WARMUP_STEPS \
--lr 1e-5 \
--weight_decay 0.1 \
--beta1 0.9 \
--beta2 0.999 \
--grad_accum_usteps $ACC_STEPS \
--print_grad_norm \
--seq_len $SEQ_LEN \
--sequence_parallel_enabled \
--selective_checkpoint_enabled \
--logging_interval 10 \
--qkv_linear \
--kv_replicator $KV_REPLICATOR \
--use_flash_attention 1 \
--checkpoint_freq $TOTAL_STEPS \
--checkpoint_dir $CHECKPOINT_DIR \
--pretrained_weight \
$EXTRA_ARGS |& tee $OUTPUT_LOG
exit ${PIPESTATUS[0]}
ファイルのパーミッションを変更します。
chmod +x tp_zero1_tanuki_8b.sh
slurmコマンドを実行してComputeNode上でスクリプトをコンパイルします。
sbatch --exclusive \
--nodes 1 \
--cpus-per-task 128 \
--wrap="srun neuron_parallel_compile ./tp_zero1_tanuki_8b.sh"
コンパイルの成功確認
squeueでジョブの状況を確認できます。
squeue
# JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
# 1 compute1 wrap ubuntu CF 0:06 1 compute1-dy-queue1-i1-1
sinfoでインスタンスの割り当てを確認します。
sinfo
# PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
# compute1* up infinite 1 alloc# compute1-dy-queue1-i1-1
# compute1* up infinite 7 idle~ compute1-dy-queue1-i1-[2-8]
なかなかノードがallocにならない場合は、CloudTrailでインスタンスの起動が成功しているかも確認されてください。
allocになった場合は、squeueからジョブが無くなるまで待ちます。完了後はHeadNodeに slurm-{ジョブID}.out というファイルにログが表示されますので、こちらでもエラーが出ていないか確認してください。
(私の場合、モジュール依存関係のエラーはこちらのログで確認しました)
実行後、以下のようなファイルができていたらOKです。
ls -l neuron_compile_cache/neuronxcc-2.15.128.0+56dc5a86/MODULE_150227667913476121+cc5101e4
# total 11588
# -rw-rw-rw- 1 ubuntu ubuntu 71 Sep 24 09:20 compile_flags.json
# -rw-rw-rw- 1 ubuntu ubuntu 0 Sep 24 09:23 model.done
# -rw-rw-rw- 1 ubuntu ubuntu 6429703 Sep 24 09:20 model.hlo_module.pb
# -rw-rw-rw- 1 ubuntu ubuntu 5428224 Sep 24 09:23 model.neff
なお今回のジョブは、完了まで約15分程度かかりました。
学習の実行
ようやく学習に入ります。以下のslurmコマンドを実行してComputeNode上で学習を実行します。
sbatch --exclusive \
--nodes 1 \
--cpus-per-task 128 \
--wrap="srun ./tp_zero1_tanuki_8b.sh"
成功の確認方法は同様ですので割愛します。
以下のようなファイルができていればOKです。
ls -ltr /fsx/checkpoints/step_100/model/
# total 2624
# drwxrwxr-x 2 ubuntu ubuntu 50176 Sep 25 05:50 dp_rank_00_tp_rank_28_pp_rank_00.pt.tensors
# drwxrwxr-x 2 ubuntu ubuntu 50176 Sep 25 05:50 dp_rank_00_tp_rank_11_pp_rank_00.pt.tensors
# ...
なお今回のジョブは、完了まで約30分程度かかりました。
学習後の後処理
以下を実行し、NeuronX DistributedのチェックポイントをTransformersのフォーマットに変換します。
export MODEL_OUTPUT_DIR=/fsx/models/tanuki-8b-sft
latest_checkpoint=$(ls ${CHECKPOINT_DIR} | sort -t_ -k2 -rn | head -n1)
python convert_checkpoints.py \
--input_dir ${CHECKPOINT_DIR}/${latest_checkpoint}/model \
--output_dir ${MODEL_OUTPUT_DIR} \
--config ${MODEL_CONFIG_PATH} \
--tp_size ${TP_DEGREE} \
--kv_size_multiplier ${KV_REPLICATOR} \
--qkv_linear True \
--load_xser True \
--convert_to_full_state True
最後に以下を実行してチャットテンプレートが書き変わったtokenizerを保存します。
temp="{% if messages[0]['role'] == 'system' %}{% set loop_messages = messages[1:] %}{% set system_message = messages[0]['content'] %}{% else %}{% set loop_messages = messages %}{% set system_message = false %}{% endif %}{% for message in loop_messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if loop.index0 == 0 and system_message != false %}{% set content = '<<SYS>>\\n' + system_message + '\\n<</SYS>>\\n\\n' + message['content'] %}{% else %}{% set content = message['content'] %}{% endif %}{% if message['role'] == 'user' %}{{ bos_token + '[INST] ' + content.strip() + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ ' ' + content.strip() + ' ' + eos_token }}{% endif %}{% endfor %}"
curl https://huggingface.co/${HF_MODEL_NAME}/raw/main/tokenizer_config.json \
| jq --arg temp "${temp}" '. + {"chat_template": $temp}' \
> ${MODEL_OUTPUT_DIR}/tokenizer_config.json
curl https://huggingface.co/${HF_MODEL_NAME}/raw/main/special_tokens_map.json -o ${MODEL_OUTPUT_DIR}/special_tokens_map.json
curl https://huggingface.co/${HF_MODEL_NAME}/raw/main/tokenizer.json -o ${MODEL_OUTPUT_DIR}/tokenizer.json
最終的な成果物
最終的な成果物は以下のようになります。こちらを推論に使用していきます。
ls -ltr /fsx/models/tanuki-8b-sft/
# total 15691041
# -rw-rw-r-- 1 ubuntu ubuntu 132 Sep 25 07:28 generation_config.json
# -rw-rw-r-- 1 ubuntu ubuntu 835 Sep 25 07:28 config.json
# -rw-rw-r-- 1 ubuntu ubuntu 9976554319 Sep 25 07:28 pytorch_model-00001-of-00002.bin
# -rw-rw-r-- 1 ubuntu ubuntu 26788 Sep 25 07:28 pytorch_model.bin.index.json
# -rw-rw-r-- 1 ubuntu ubuntu 6084084154 Sep 25 07:28 pytorch_model-00002-of-00002.bin
# -rw-rw-r-- 1 ubuntu ubuntu 3581 Sep 25 07:36 tokenizer_config.json
# -rw-rw-r-- 1 ubuntu ubuntu 968 Sep 25 07:36 special_tokens_map.json
# -rw-rw-r-- 1 ubuntu ubuntu 4255249 Sep 25 07:36 tokenizer.json
まとめ
いかがでしたでしょうか。本記事ではParallelClusterの活用として、別記事を参考にTrainiumを使ったLLMの学習を実施しました。
Inferentiaを使った推論も引き続きやってみたいと思います。
本ブログがご参考になれば幸いです。










